26.07 World Model
The 26.07 release of our World Model consists of three small vision models from three very different parts of the world - China, France and United States.

| Ollama Model | Size | Month | Role |
|---|---|---|---|
| qwen3-vl:4b-instruct-q4_K_M | 3.3 GB | 2025-11 | Primary |
| ministral-3:3b-instruct-2512-q4_K_M | 3.0 GB | 2025-12 | Secondary |
| gemma3:4b-it-qat | 4.0 GB | 2025-05 | Secondary |
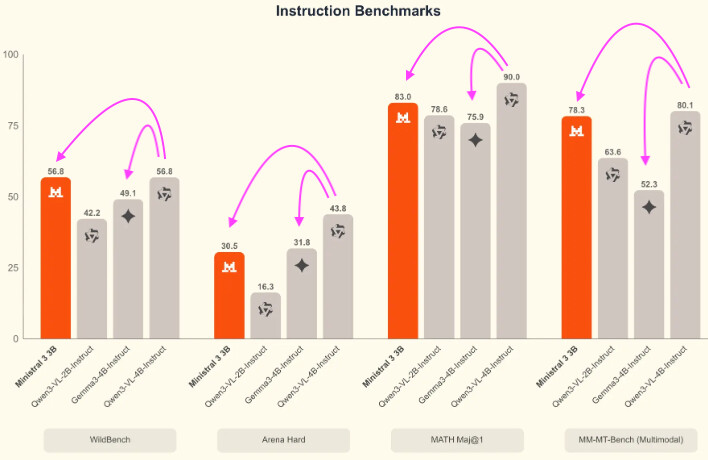
qwen3-vl:4b has the best benchmark scores and will be the primary model controlling the other two models.
qwen3-vl-4b-instruct
- Qwen
- Qwen/Qwen3-VL-4B-Instruct · Hugging Face
- GitHub - QwenLM/Qwen3-VL: Qwen3-VL is the multimodal large language model series developed by Qwen team, Alibaba Cloud. · GitHub
ministral-3-3b-instruct-2512
gemma-3-4b-it
Ollama Limitations
Ollama has a lot of limitations, the situation will improve once we started to add VLLM and LM Studio into the backend LLM server mix.
-
Ollama does NOT support a lot of vision models, so our vision model options are limited here.
-
Ollama does NOT support the large context windows of many models e.g. Qwen3-VL-4B has 256K native context size but Ollama only supports 4K.